Extracting Chinese Hard Subs from a Video, Part 1
I’ve been watching the Chinese TV show 他来了,请闭眼 (Love Me If You Dare). It’s a good show, kinda reminiscent of the BBC series Sherlock, likewise a crime drama centered around an eccentric crime-solving protagonist and a sympathetic sidekick. You should check it out if you’re into Chinese film or are learning Chinese and want something interesting to watch.
I wanted to get a transcript of the episode’s dialog so I could study the unfamiliar vocabulary. Unfortunately, the video files I have only have hard subtitles, i.e. the subtitles are images directly composited into the video stream. After an hour spent scouring both the English- and Chinese- language webs, I couldn’t find any soft subs (e.g. SRT format) for the show.
So I thought it’d be interesting to try to convert the hard subs in the video files to text. For example, here’s a frame of the video:

From this frame, we want to extract the text “怎么去这么远的地方“. To approach this, we’re going to use the Tesseract library and the PyOCR binding for it.
We could just try throwing Tesseract at it and see what comes out:
import pyocr
from PIL import Image
LANG = 'chi_sim'
tool = pyocr.get_available_tools()[0]
print(tool.image_to_string(Image.open('car_scene.png'), lang=LANG))Running it:
$ python snippet_1.py
$ Hmm, so that didn’t work. What’s happening?
Tesseract requires that you clean your input image before you do OCR. Our input image is full of irrelevant background features but Tesseract expects clean black text on a white background (or white on black).
To remove the background image and get just the subtitles, we turn to OpenCV. The easiest part is cropping the image. We keep a larger left/right border because some frames have more text:
import cv2
TEXT_TOP = 621
TEXT_BOTTOM = 684
TEXT_LEFT = 250
TEXT_RIGHT = 1030
img = cv2.imread('car_scene.png')
cropped = img[TEXT_TOP:TEXT_BOTTOM, TEXT_LEFT:TEXT_RIGHT]
cv2.imshow('cropped', cropped)
cv2.waitKey(10000)The result:

Now we want to isolate the text. The text is white, so we can mask out all the areas in the image that aren’t white:
white_region = cv2.inRange(cropped, (200, 200, 200), (255, 255, 255))This uses the OpenCV inRange function. inRange returns a value of 255 (pure white in an 8-bit grayscale context) for pixels where the red, blue, and green components are all between 200 and 255, and 0 (black) for pixels that are outside this range. This is called thresholding. Here’s what we get:
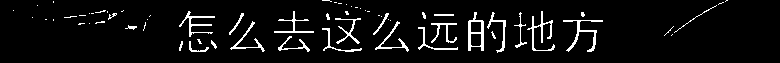
A lot better! Let’s run Tesseract again:
extracted_text = tool.image_to_string(Image.fromarray(white_region), lang=LANG)
print(extracted_text)And Tesseract returns (drumroll…):
′…′二′′′'′ 怎么去逯么远的地方 '/′Now we’re getting somewhere! Several areas in the background are white, so when we pass those through to Tesseract it interprets them as assorted punctuation. Let’s strip out these non-Chinese characters using the built-in Python unicodedata library:
import unicodedata
chinese_text = []
for c in extracted_text:
if unicodedata.category(c) == 'Lo':
chinese_text.append(c)
chinese_text = ''.join(chinese_text)
print(chinese_text)The 'Lo' here is one of the General Categories that Unicode assigns to characters and stands for “Letter, other”. It’s good for extracting East Asian characters. From this code we get:
二怎么去逯么远的地方There are two mistakes here: a spurious 二 character on the front, and a mismatched character in the middle (that 逯 should be 这). Still, not bad!
That’s all for now, but in Part 2 (and maybe Part 3?) of this post series I’ll discuss how we can use some more advanced techniques to perfect the above example and also handle cases where extracting the text isn’t so straightforward. If you can’t wait until then, the code is on GitHub.
If you have any comments about this post, join the discussion on Hacker News, and if you enjoyed it, please upvote on HN!