I enjoy micro-optimizing things, so I have a device that tells me when to leave my apartment to catch the train. At 10:53 AM, it told me to leave, so I did; it was lining me up for a train scheduled to depart at 11:01 AM. The station is 10 minutes away walking but the transit panel thought the train was running 2 minutes late.
At the station I waited about 2 minutes for the train to appear and another 2 for it to leave once I boarded. 4 minutes 1 of precious time which could have been spent blogging was instead wasted waiting in the near-freezing station. What happened—why did my transit panel mislead me so?
A system’s output is only as good as the input you feed to it, and it turns out the transit panel was itself misled by the API it was using to get realtime PATH departures. That API had an overly-optimistic view of how late the train was running. Let’s look at the data!
Here’s a graph of how many minutes were left before the train departed according to 4 sources, in the 10-odd minutes leading up to departure:
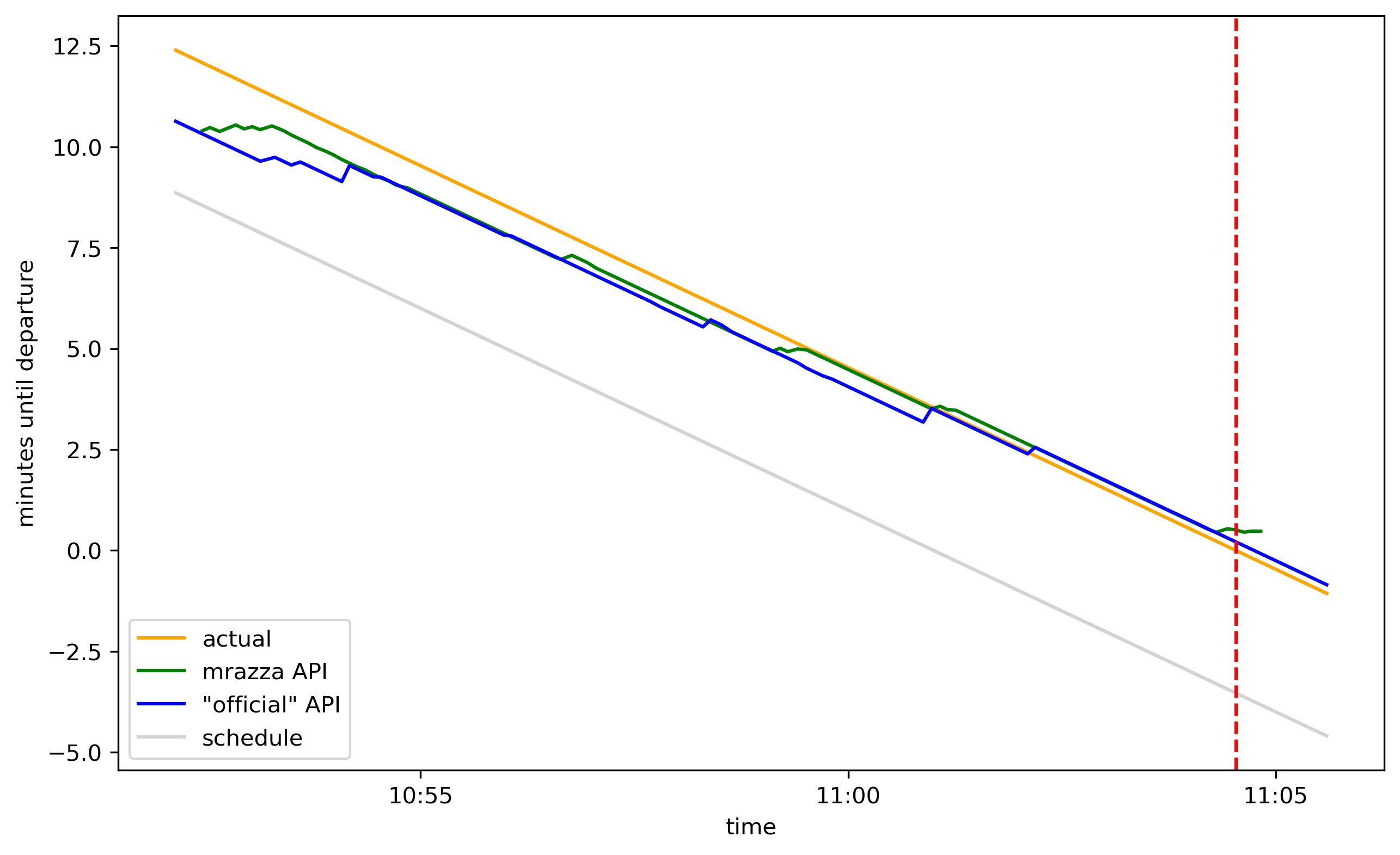
The gray line is how much time was left until departure according to the train schedule. By “departure” I mean when the doors closed. The green line uses data from an API made by Matt Razza.2 The blue line uses data from an “official” API.3 The orange line is the actual time left (as if we had a crystal ball which knew the exact departure time). The dashed red line is the departure.
This graph is easier to interpret if you instead look at how late the sources predict the train will be:
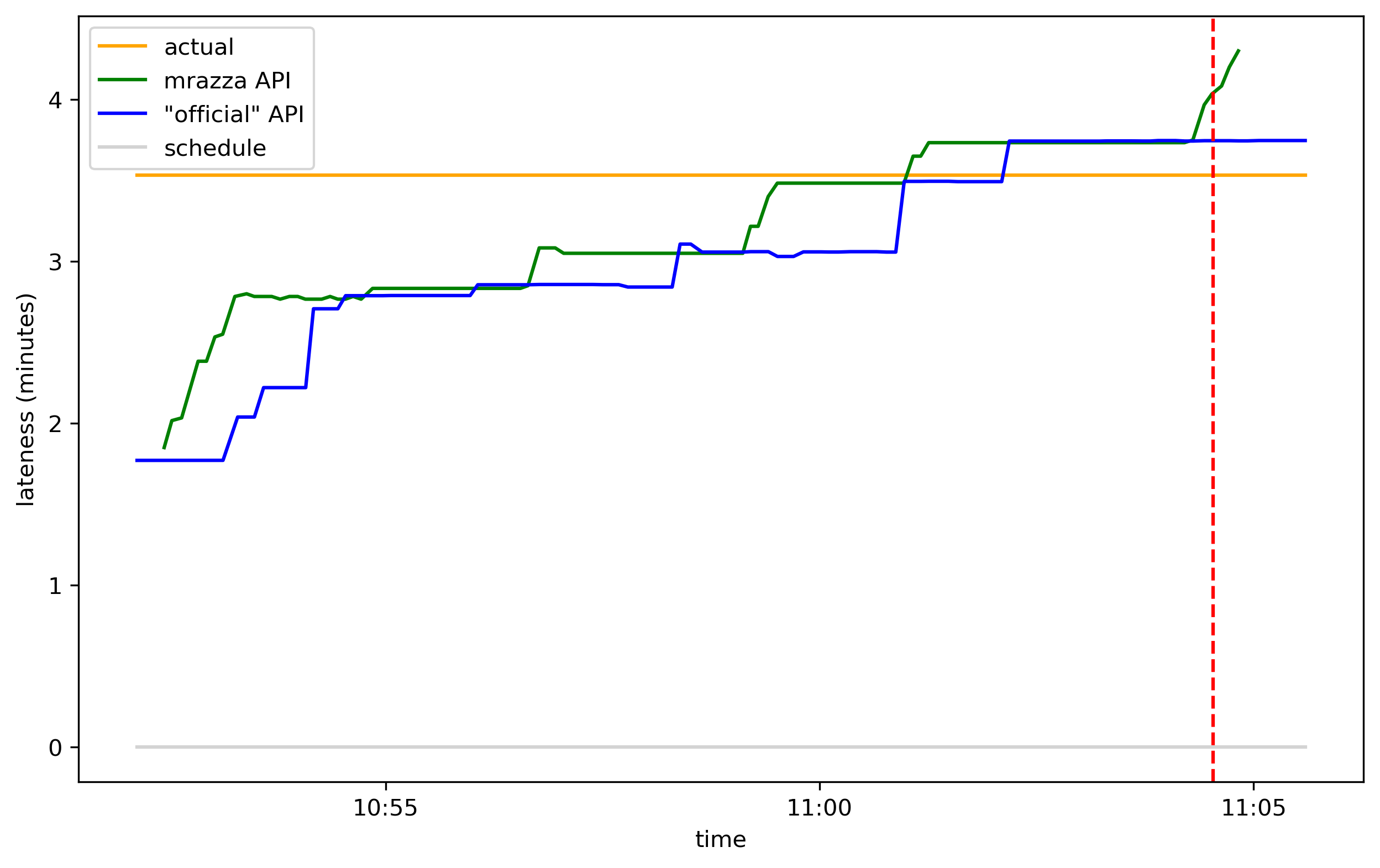
The train was ultimately 3m32s late, but intially the two APIs estimated it at 1m48s late. As the actual departure time drew closer, the APIs became more accurate and eventually overshot, predicting it would leave 13 seconds after it did.4
To catch the train I needed to leave 10 minutes before departure. Here’s what that looks like superimposed on the first graph:
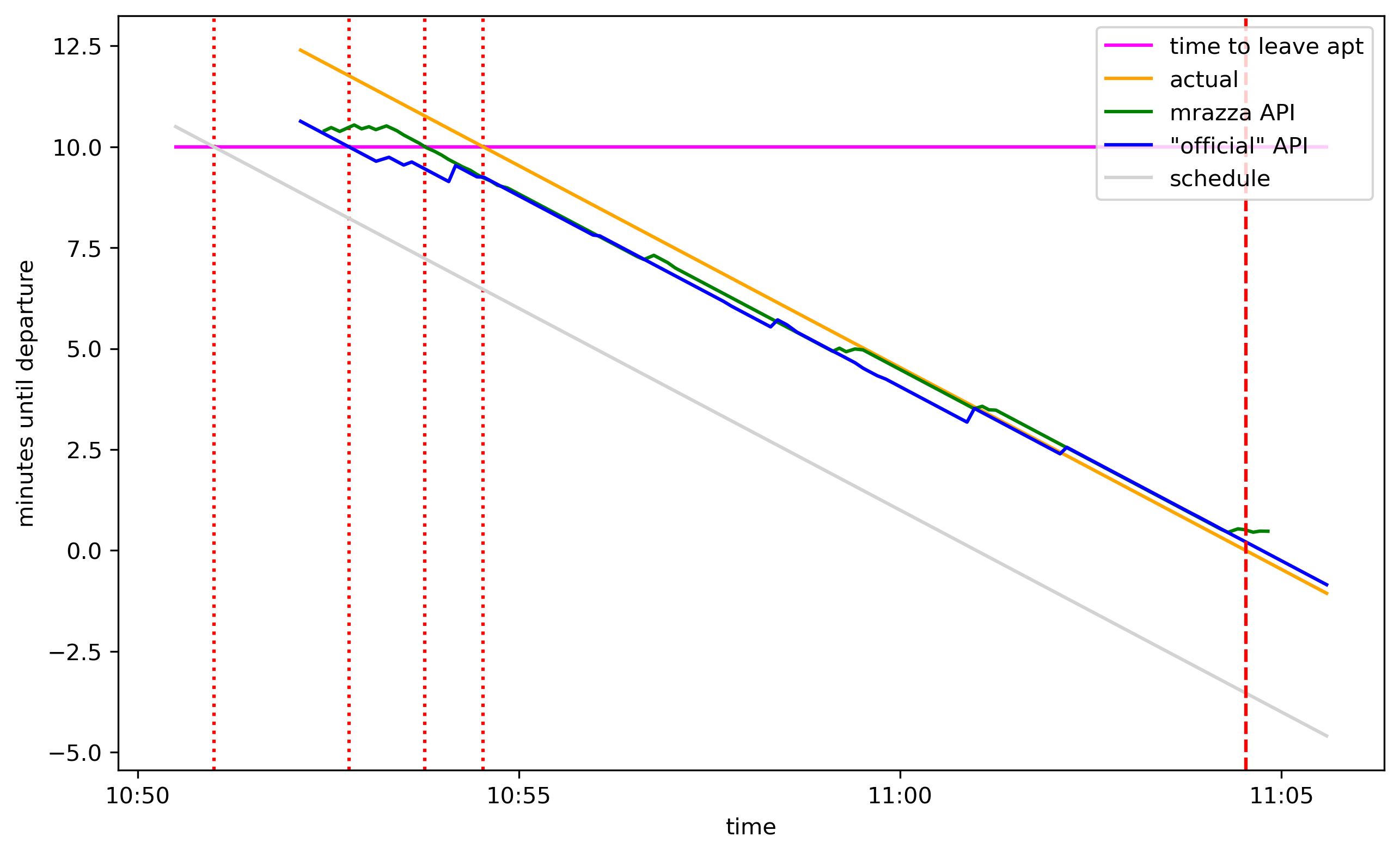
The intersections of the magenta line with the 4 timelines are the times I should leave my apartment according to these 4 sources:
| source | when to leave according to source |
|---|---|
| schedule | 10:51:00 |
| "official" API | 10:52:46 |
| mrazza API | 10:53:46 |
| ground truth | 10:54:32 |
Following the schedule, I would have left 3m32s too early. Since my transit panel uses the “official” API, I was able to save half of that. If mrazza’s API—which gives better data (see below) but is down—were available, I could have saved another minute. And if the API made perfect predictions, it would have saved the remaining 46 seconds.
Squinting at that second graph, the “official” API looks an awful lot like a lagged version of Matt Razza’s API. Indeed, if we scoot it ahead 80 seconds, we see that it aligns pretty well:
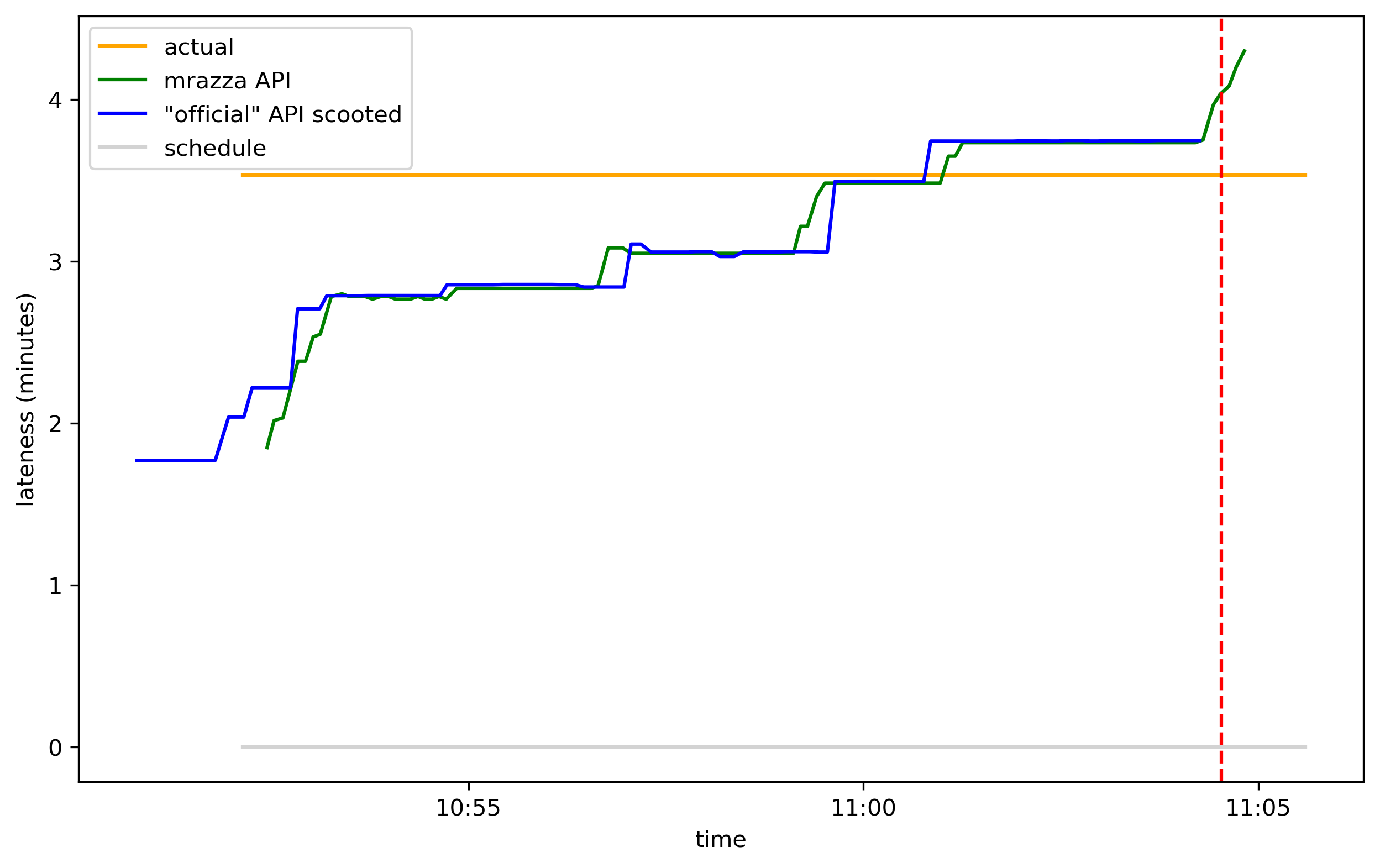
I hypothesize that the same data source feeds both the mrazza and “official” APIs (Matt’s blog post has more information about the data infra that PATH uses on the backend) and something in the “official” API adds a random delay of 70 to 90 seconds. So if you’re looking at the real-time departures on PATH’s website, the info you’re looking at is a little stale compared to what the backend actually knows.
That’s all for now,5 but maybe in a future episode I’ll revisit the data that we get from PATH’s API. The Jupyter notebook where I did this analysis is here. The scraper that recorded the data is here. To record the train departure time I used a simple Google Form (Google Forms records the timestamp when you submit a form).
-
There’s a 2-minute buffer baked into the 10 minute walk time, so I only waited an extra 2 minutes here.6 You maybe noticed that I waited 4 minutes but the API’s error only explained ~2 minutes. Can’t let a technicality interrupt my narrative flow. ↩
-
mrazza’s API is currently down so I hosted it locally to collect data, but my transit panel doesn’t use it. ↩
-
The “official” API is at https://www.panynj.gov/bin/portauthority/ridepath.json. I’m using scare quotes because I don’t think this API is meant for public consumption: it’s made for displaying realtime info on panynj.gov. It lacks an
Access-Control-Allow-Origin: *header and so I have to run a proxy on my Raspberry Pi in order to access it from my transit panel web app. ↩ -
Maybe the APIs use some other definition of “departure”? I think “the time the doors close” is the definition they should be using because it’s the most relevant to me as a rider, but maybe they use “the time the train starts moving”? ↩
-
Here’s a bonus graph, showing lateness like the 2nd graph but adding the magenta line. The magenta line has a slope of positive 1 in these transformed coordinates:
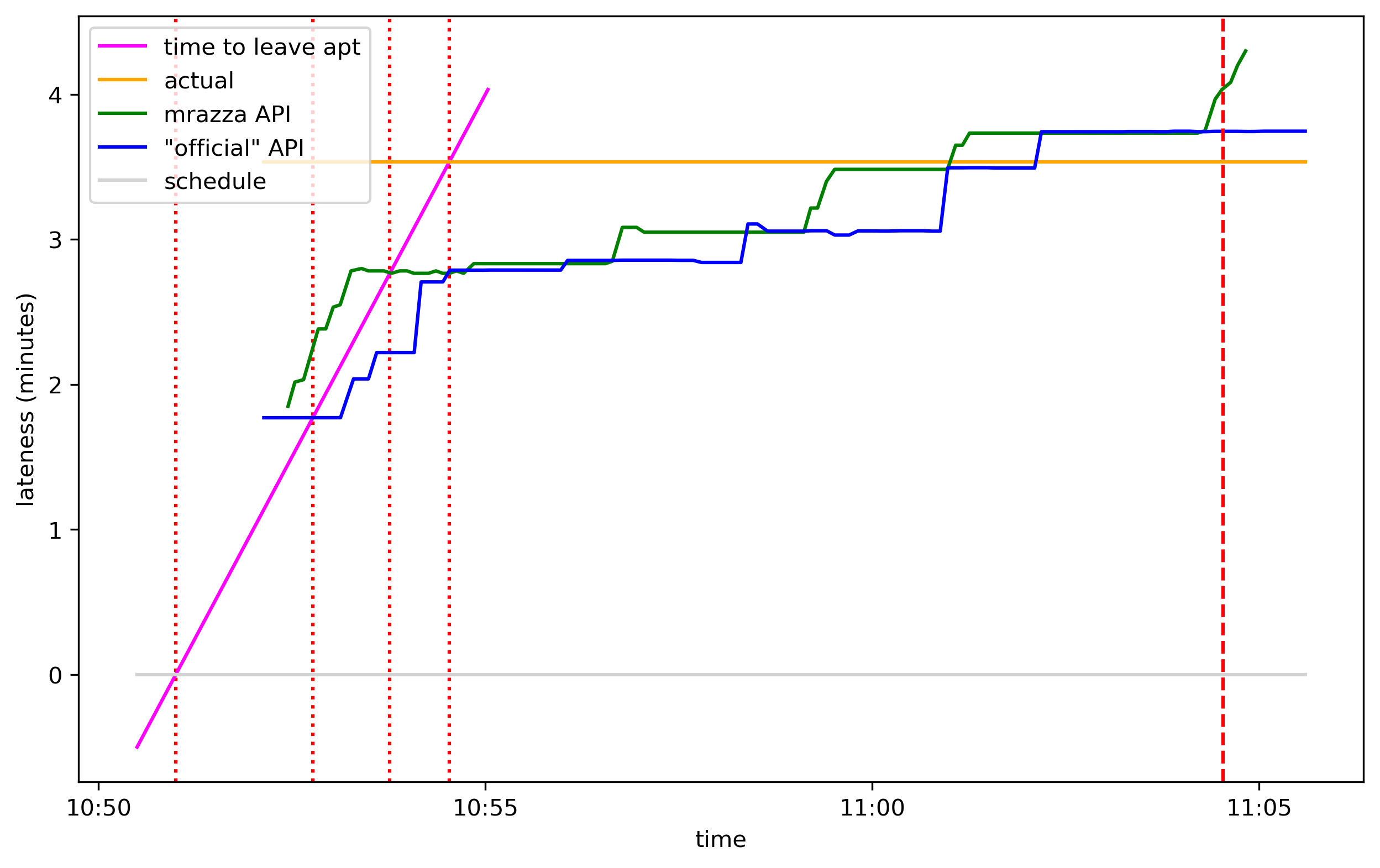 ↩
↩ -
I’ve probably spent more time working on the transit panel and blogging about it than it will ever save me, but eh, you have to find something to spend your time on. ↩
 2 minutes before departure, train waiting in station
2 minutes before departure, train waiting in station
 mount with tablet removed
mount with tablet removed